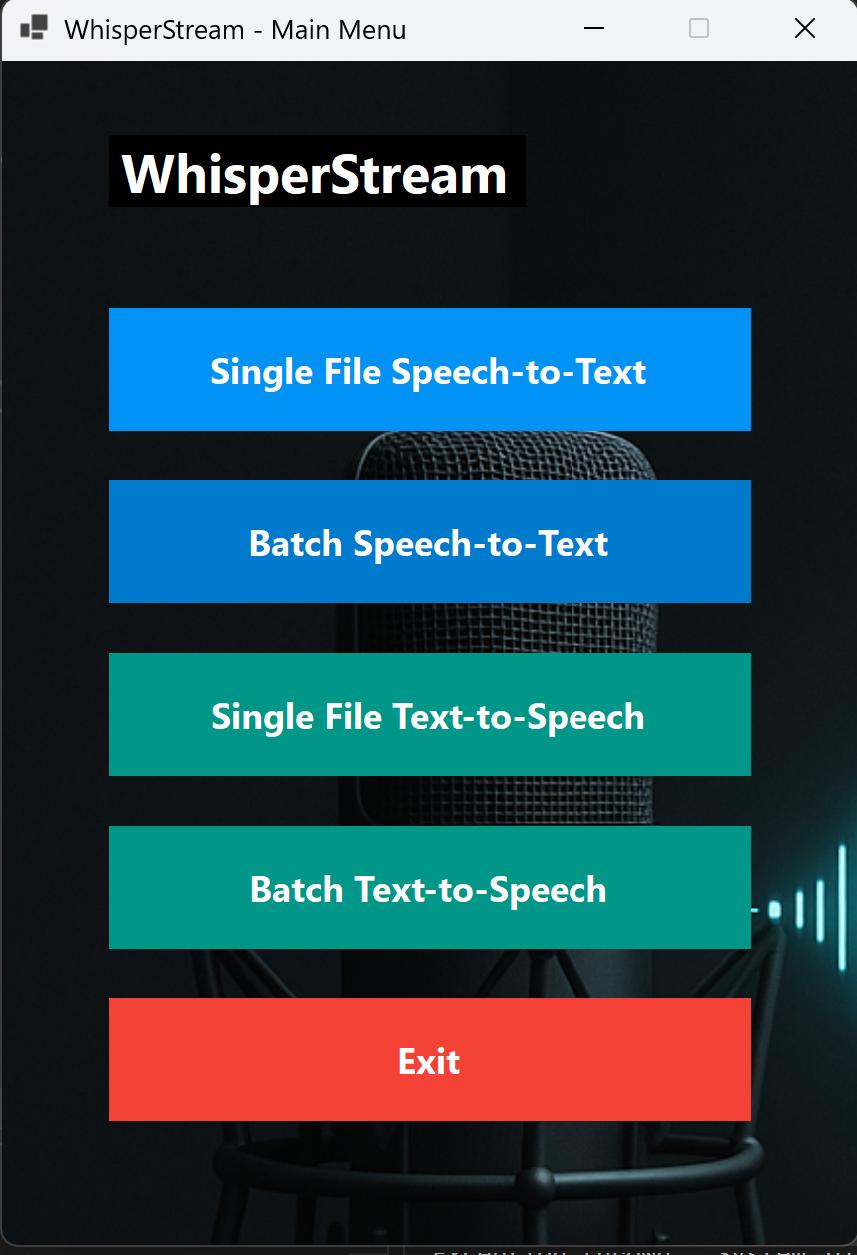
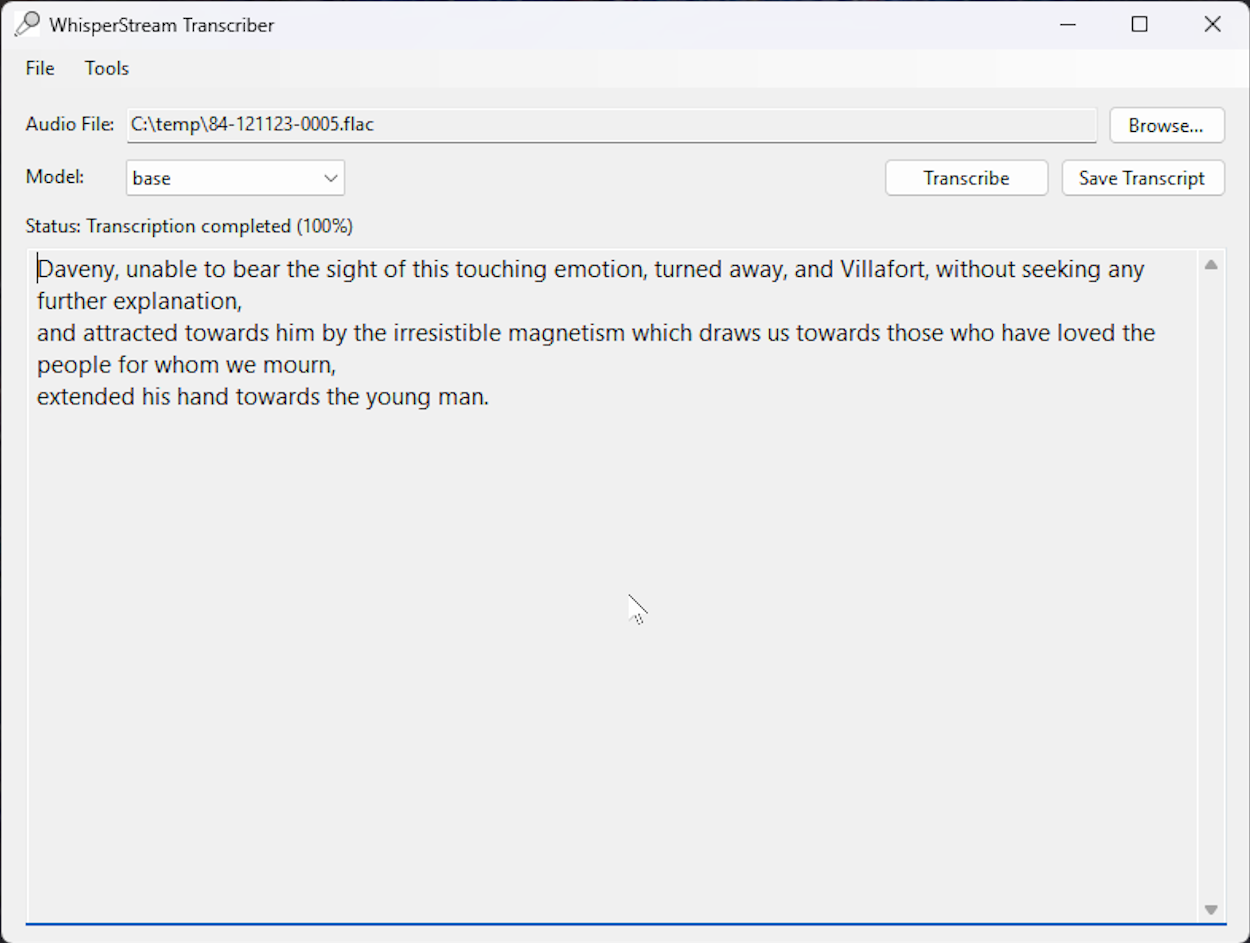
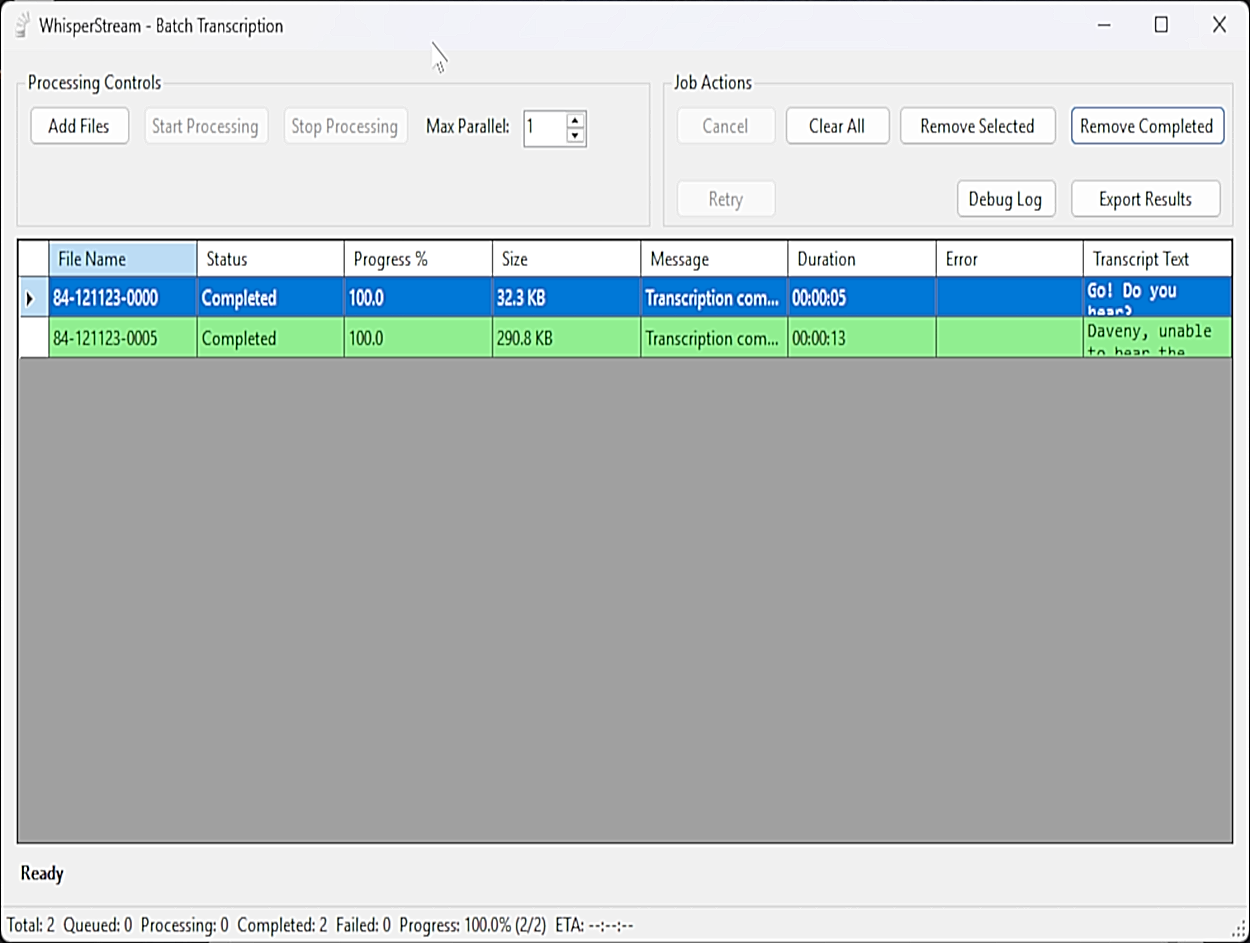
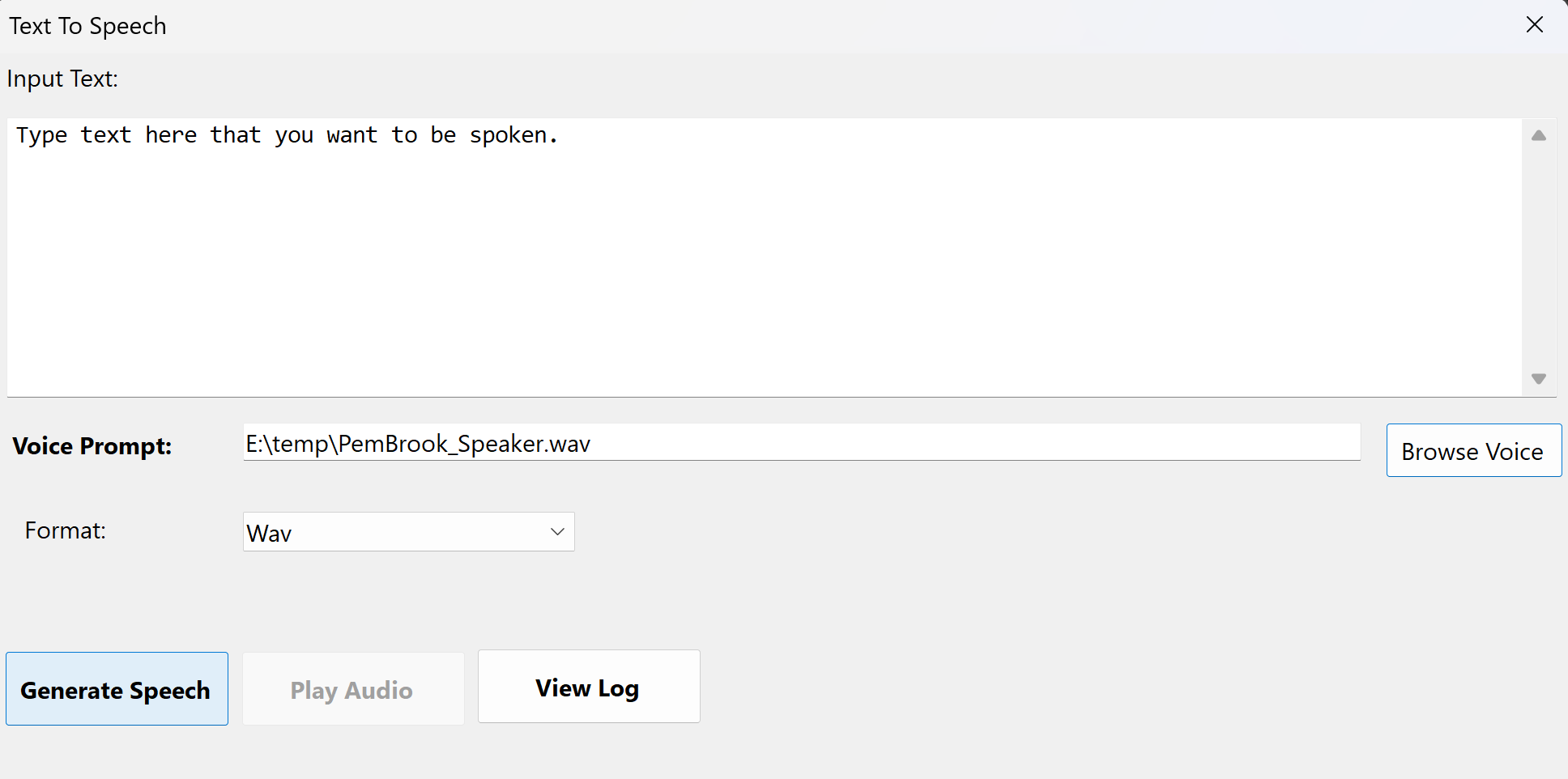
Turn Your Voice Into Text — And Text Into Voice
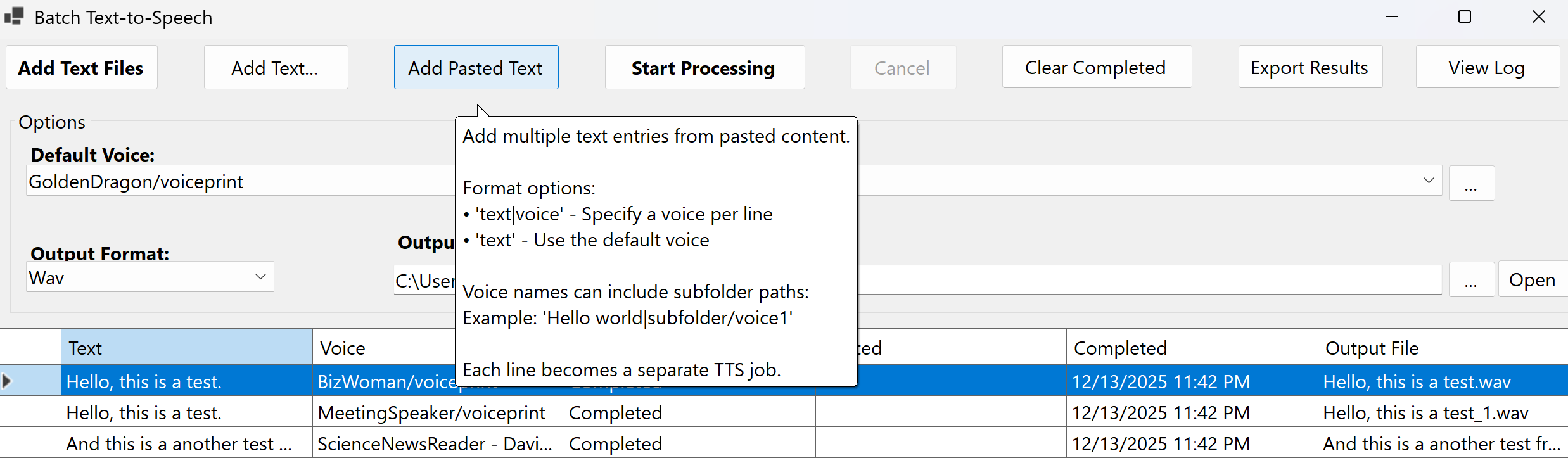
WhisperStream is your complete audio solution, featuring both speech-to-text transcription and text-to-speech synthesis using Chatterbox voice mimic technology.
WhisperStream is a download available to all Story Runner members.
Join today!
Become a Story Runner